Automatic Speech Recognition ≠ Natural Language Understanding
Most voice-based systems like Apple Siri, Google Voice and some others such as Samsung S-Voice, are conventionally, and not quite correctly, referred to as “speech recognition systems”. The performance of these systems goes beyond the mere recognition of spoken language. They are also able to comprehend the meaning behind a speaker’s utterance.
Experts use the term Natural Language Understanding (NLU), as distinguished from Automatic Speech Recognition (ASR). In order to understand anything, NLU obviously relies on the input from the ASR – how and why, we are going to describe in the following.
Human speech is, first of all, an acoustic signal with a specific pattern which carries meaning for certain sounds and strings of sounds. The phonetic representations of the German word “Bild” (image), for example, consists of the individual contrastive units, or phonemes /b/, /i/, /l/ and /d/. A closer consideration, which conveys the phonetic reality more faithfully, represents its sounds as [bɪlt]. Note that the grapheme , due to the final obstruent devoicing characteristic to the German language, will be pronounced as .
An Automatic Speech Recognizer (ASR) renders this acoustic signal (which might be subject to variations) into a machine-readable form. Image 1 shows the acoustic form of the German word „Bild“ in a so-called spectrogram. It shows the distribution of energy from the acoustic signal across the frequency band (y-axis) and time (x-axis).
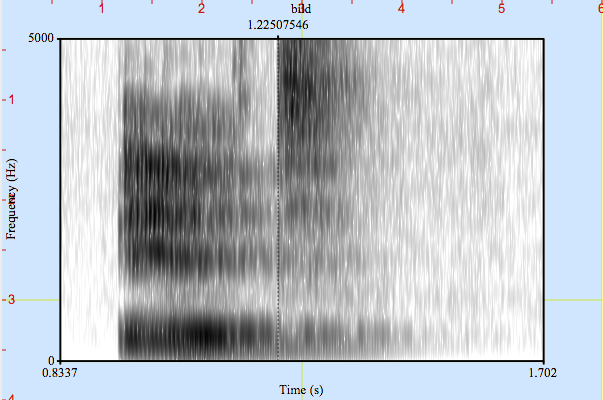
The spectrogram reflects quite clearly the parting of the lips at the beginning of “b”, the high energy in the lower frequencies, and the subsequent production of “i” (/ɪ/) and the strong, high-frequency energy during the aspirated “t” after the first half of the signal after circa 1,22 seconds. This pattern, which is the visual representation of the word “Bild”, is recognized as [bɪlt], i.e. its phonetic representation, by the ARS, and transformed into the string “B-i-l-d”.
This, in essence, is the task of the automatic speech recognition. No machine, no computer knows what this string of graphemes actually means. There are two approaches to attach meaning to it.
- Keyword Spotting: The software developer allocates a meaning to specific strings such as “navigation” or „radio“ or “louder” by linking a particular machine response to a certain key word. If the ASR recognizes „radio“ and „louder“, the machine can either turn the volume up by a certain level or check with the user first by asking “Shall I increase the radio’s volume by XY?”. It is quite easy to see that this is not a viable approach, considering the infinite variety of conceivable intentions and their nuances: the complexity of natural language understanding and dialog management requires unlimited resources for the programming of such a system or will lead to its early collapse.
- Natural Language Understanding (NLU) enables machines to learn and thus be able to comprehend the user’s intention intelligently and according to specific contexts, and react accordingly. Ontology-based semantics enable machines to learn what users really mean.
NLU alone enables a system to intelligently comprehend, adapt, and perform proactive assistance functions. Mere voice recognition is hardly helpful in this respect. In addition, NLU helps not only to understand the intention of the user better, but also to recognize the language more robustly – if the system knows and understands the (thematic, local and temporal) context and understands particular meanings in that domain, it can support the ASR in precluding nonsensical interpretations of the acoustic signal.
The gap between humans and technology is becoming larger – humans beings are often not even aware of the entire range of options offered by a technological device, let alone understand how to use them. Voice control and speech dialog systems can help to close this gap. We use words to convey our intention – as soon as machines are able to understand what we are saying, they can perform major parts of our work.