Automatic Speech Recognition ≠ Natural Language Understanding
Die meisten sprachbasierten Systeme wie Apple Siri, Google Voice und einige andere wie zum Beispiel Samsungs S-Voice werden im allgemeinen Sprachgebrauch gerne und oft zumindest nicht ganz korrekt als „Spracherkennungssysteme“ bezeichnet. Denn eigentlich leisten die genannten Systeme ja mehr, als gesprochene Sprache nur zu erkennen. Sie sind zusätzlich dazu in der Lage, die Bedeutung dessen, was der Nutzer/die Nutzerin gesagt hat, zu verstehen.
In der Fachwelt spricht man hier von Natural Language Understanding (NLU) in der weitergehenden Unterscheidung zur reinen Spracherkennung (Automatic Speech Recognition, ASR). Natürlich braucht eine NLU den Input der ASR, um überhaupt etwas verstehen zu können – wieso und warum, skizzieren wir im Folgenden.
Menschliche Sprache ist zuerst einmal ein akustisches Signal, das für gewisse Laute und damit auch Lautketten, die für Menschen bedeutungstragend sind, spezifische Muster aufweist. Das Wort „Bild“ zum Beispiel besteht sehr oberflächlich phonemisch (lautlich) repräsentiert aus den einzelnen bedeutungsunterscheidenden Lauten /b/, /i/, /l/ und /d/. In einer etwas engeren Betrachtung, die der phonetischen Realität eher entspricht, ist die Lautlichkeit [bIlt] – zu beachten ist hier, dass das Graphem „d“ im deutschen aufgrund der Auslautverhärtung als „t“ ausgesprochen wird.
Ein Spracherkenner tut nun nichts anderes, als dieses (je nach Sprecher leicht bis stark variierenden) akustischen Muster in eine maschinenlesbare Form – einen „String“ von Zeichen – zu bringen. In Abbildung 1 sehen Sie die akustische Form des Wortes „Bild“ im sogenannten Spektrogramm. Es zeigt die Energieverteilung des akustischen Signals über das Frequenzband (y-Achse) und die Zeit (x-Achse).
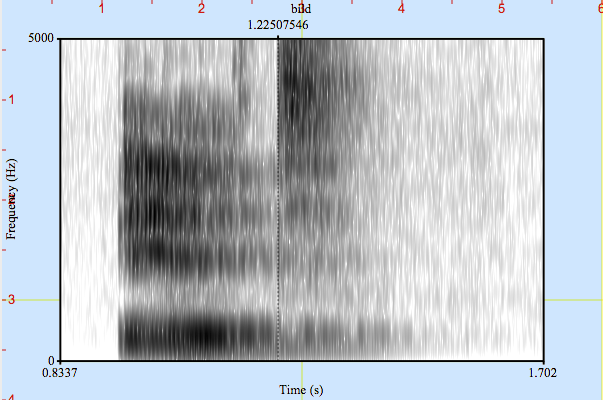
Schön zu sehen ist das Lösen der Lippen zu Beginn des „b“, die recht hohe Energie im unteren Frequenzbereich während der darauf folgenden Realisierung des „i“ und die starke hochfrequente Energie während des aspirierten „t“ ab etwa der Hälfte des Signals nach 1,22 Sekunden. Dieses für uns hier visualisierte Muster, sozusagen das optische Abbild des Wortes „Bild“, erkennt der Spracherkenner im ASR-Prozess als phonemische Repräsentation [bIlt] und wandelt diese in den String „B-i-l-d“ um.
Das und erst einmal nichts anderes ist die Aufgabe eines Spracherkenners. Keine Maschine, kein Computer WEISS, was das bedeutet. Nun gibt es zwei Ansätze, dem String aus Graphemen so etwas wie eine Bedeutung zu geben.
- Keyword Spotting: Der Programmierer gibt dabei bestimmten Strings wie zum Beispiel „Navigation“ oder „Radio“ oder „lauter“ eine Bedeutung, indem er eine bestimmte Aktion der Maschine mit der Erkennung des entsprechenden Schlüsselwortes verknüpft. Erkennt die ASR „Radio“ und „lauter“, so kann die Maschine entweder direkt das Radio um einen festgelegten Wert lauter machen oder zur Bestätigung eine Rückfrage „Soll ich das Radio um XY lauter machen?“ generieren. Man kann sich vorstellen, dass dieser Ansatz für die unendliche Vielfalt an möglichen Intentionen und deren Nuancen wenig praktikabel ist: Die große Komplexität der natürlichsprachlichen Bedienung und Dialogführung erforderte hier unendliche Ressourcen für die Programmierung eines solchen Systems beziehungsweise brächte es frühzeitig zum Absturz.
- Mit Natural Language Understanding (NLU) können Maschinen Bedeutungen lernen und so intelligent und kontextspezifisch Intention erkennen und entsprechend reagieren. Über eine Semantik, die sich auf Ontologien stützt, lernt die Maschine, was der Nutzer oder die Nutzerin wirklich meint.
Nur mit NLU kann ein System also intelligent verstehen, adaptiv reagieren und proaktive Assistenzfunktionen durchführen. Reine Spracherkennung hilft dabei nicht weiter. Zusätzlich hilft NLU dabei, nicht nur die Intention des Nutzers besser zu verstehen, sondern auch die Sprache robuster zu erkennen – wenn das System den (thematischen und lokalen sowie zeitlichen) Kontext kennt, versteht und weiß, was innerhalb der Domäne Sinn ergibt, kann es dem Erkenner dabei helfen, unsinnige Interpretationen des akustischen Signals von vorneherein auszuschließen.
Die Lücke zwischen Mensch und Technik wird immer größer – der Mensch kennt oft nicht einmal alle Möglichkeiten, die ein technisches Gerät ihm bietet, geschweige denn weiß er, wie sie zu nutzen sind. Sprachsteuerungs- und Sprachdialogsysteme können dabei helfen, diese Lücke zu schließen. Wir benutzen Worte, um unsere Intention zum Ausdruck zu bringen – wenn eine Maschine dies versteht, kann ein Großteil der Arbeit auch von ihr übernommen werden.