Fast and efficient extraction of information from large data volumes is the basis for search engines as we know and use them today. One problem for these solutions, however, are questions entered as complete sentences and in natural language. A simple and precise response to such input is no simple matter.
In his MA-Thesis “Question Answering System Using Wikidata as a Knowledge Base” (Saarland University), SemVox-developer Almer Bolatov has explored the potential of limiting the number of NLU-templates (patterns for the recognition of natural language, s. Natural Language Understanding) and fine-tuning search algorithms over several test repetitions for improving results in in question-answering-systems .
Question-answering systems allow users to enter questions in natural language and receive a precise, exact response instead of a list of search results. This form of information retrieval will gain importance as it is becoming more difficult to find relevant information on the internet with conventional search engines.
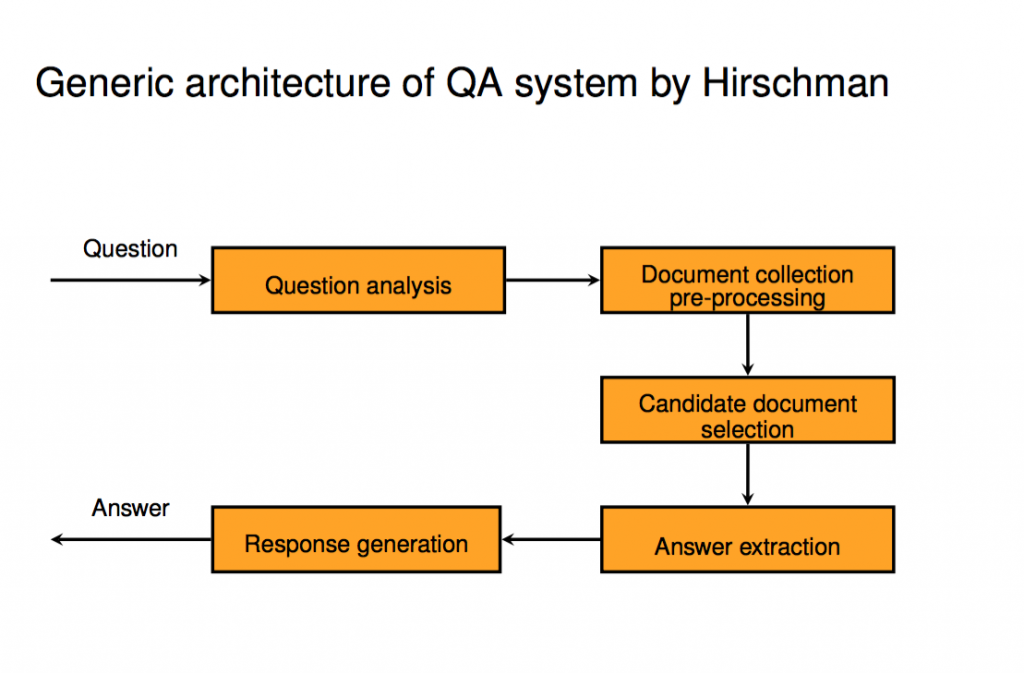
Question-answering systems have, in principle, always the same structure: first, the question entered by a user is semantically analysed and the database (document collection) preprocessed in search for the result of the semantic analysis. Thereby, the „best candidates“ for an answer are pre-selected and the correct answer is extracted. The final step is the generation of the response (image 1).
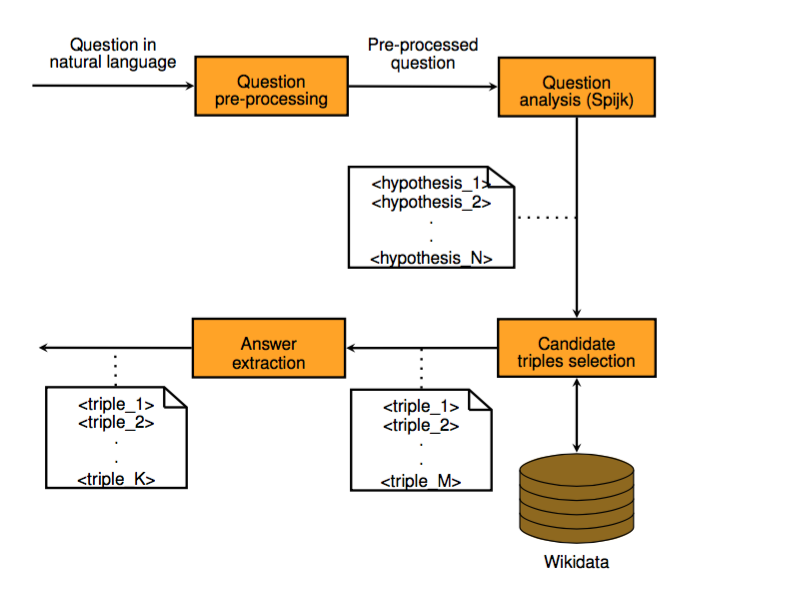
In his thesis, Almer Bolatov has used Wikidata as the knowledge base for his question-answering system. Wikidata is a structured knowledge source where each item is identified by a unique ID-number. It is open source and any piece of information is provided in various languages, and (in contrast to Wikipedia, for instance), the scope of information remains the same in each language.
Almer Bolatov based his approach on the Wizard-of-Oz-Studies to gain insight into human and machine behavior in question-answering-processes, to collect questions by users documented in the studies and compile a corpus of patterns for the analysis of the questions.
In a second step, he developed an algorithm for the processing of the questions and ran a test for his NLU-patterns in three successive iterations. After each iteration, he adjusted the algorithms and NLU-templates according to the respective previous outcomes to improve the results of the question-answering machine.
His studies showed that the implemented system is able to process a limited number of question types. Another result is the improvement of the deployed algorithm and the NLU-templates in the three test-iterations: the first version of the question-answering-system could answer more than 50% of the questions, but errors occurring because of missing question patterns (NLU-Templates), could be reduced from 10,53% in the first round to 6,74% in the second and only 5,81% in the third round. The remaining errors (incorrectly answered questions) could be traced back to misspelled questions and thus to the question-answering system itself.
Through studies such as these, SemVox receives a steady input from cutting edge research. The value of the fresh ideas and innovative creativity of the SemVox-team is directly reflected in the products and solutions. Cutting edge innovations are indispensable for a portfolio which remains world-wide unmatched.